

[ad_1]
Anthropic / Benj Edwards
On Thursday, Anthropic introduced Claude 3.5 Sonnet, its newest AI language mannequin and the primary in a brand new collection of “3.5” fashions that construct upon Claude 3, launched in March. Claude 3.5 can compose textual content, analyze knowledge, and write code. It encompasses a 200,000 token context window and is out there now on the Claude website and thru an API. Anthropic additionally launched Artifacts, a brand new characteristic within the Claude interface that reveals associated work paperwork in a devoted window.
Up to now, folks exterior of Anthropic appear impressed. “This mannequin is actually, actually good,” wrote unbiased AI researcher Simon Willison on X. “I feel that is the brand new greatest general mannequin (and each quicker and half the value of Opus, much like the GPT-4 Turbo to GPT-4o soar).”
As we have written before, benchmarks for big language fashions (LLMs) are troublesome as a result of they are often cherry-picked and infrequently don’t seize the texture and nuance of utilizing a machine to generate outputs on nearly any conceivable subject. However in accordance with Anthropic, Claude 3.5 Sonnet matches or outperforms competitor fashions like GPT-4o and Gemini 1.5 Professional on sure benchmarks like MMLU (undergraduate stage information), GSM8K (grade faculty math), and HumanEval (coding).
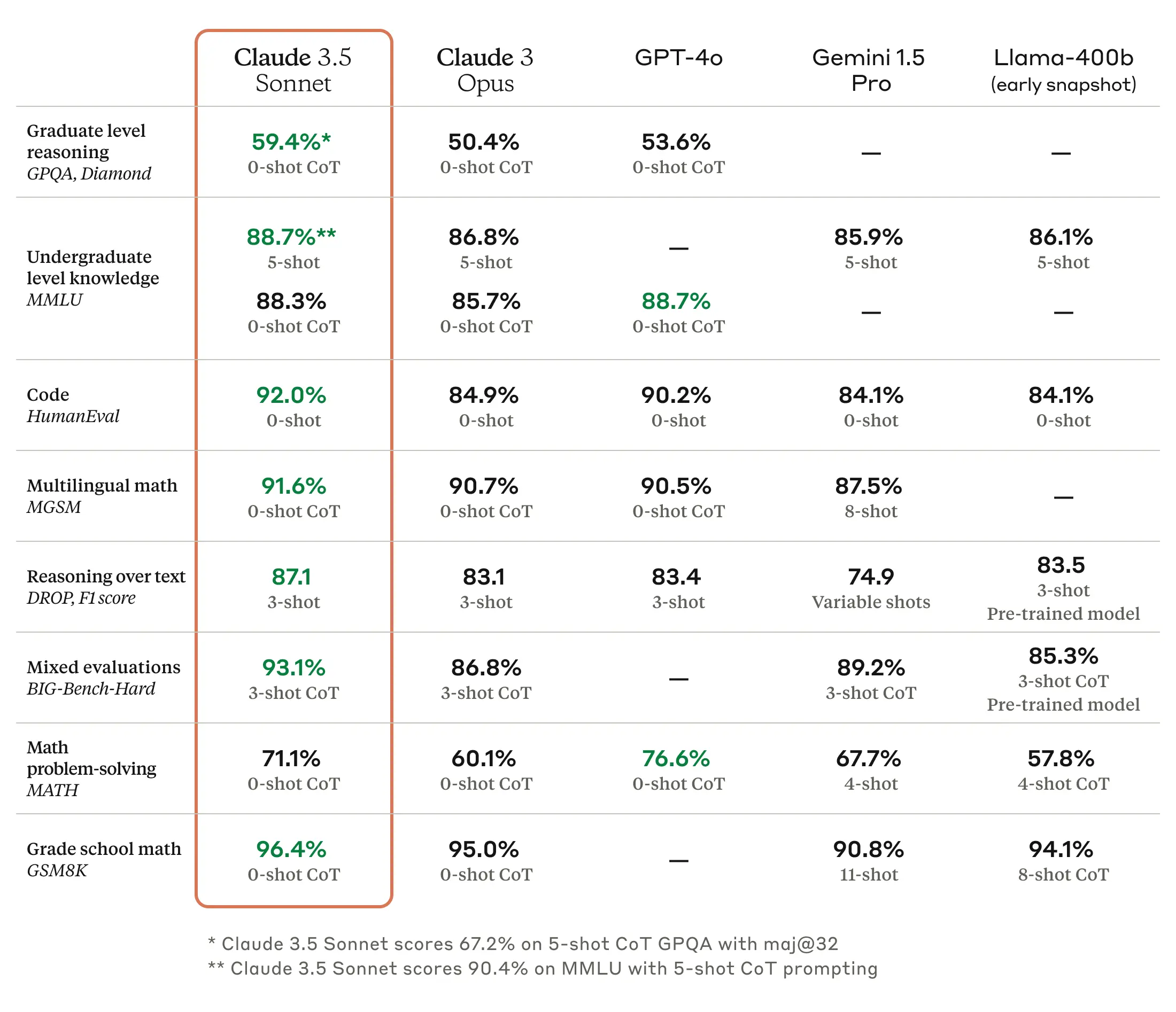
If all that makes your eyes glaze over, that is OK; It is significant to researchers however largely advertising and marketing to everybody else. A extra helpful efficiency metric comes from what we would name “vibemarks” (coined right here first!) that are subjective, non-rigorous mixture emotions measured by aggressive utilization on websites like LMSYS’s Chatbot Area. The Claude 3.5 Sonnet mannequin is currently under evaluation there, and it is too quickly to say how properly it can fare.
Claude 3.5 Sonnet additionally outperforms Anthropic’s previous-best mannequin (Claude 3 Opus) on benchmarks measuring “reasoning,” math abilities, normal information, and coding skills. For instance, the mannequin demonstrated robust efficiency in an inside coding analysis, fixing 64 % of issues in comparison with 38 % for Claude 3 Opus.
Claude 3.5 Sonnet can also be a multimodal AI mannequin that accepts visible enter within the type of pictures, and the brand new mannequin is reportedly wonderful at a battery of visible comprehension exams.
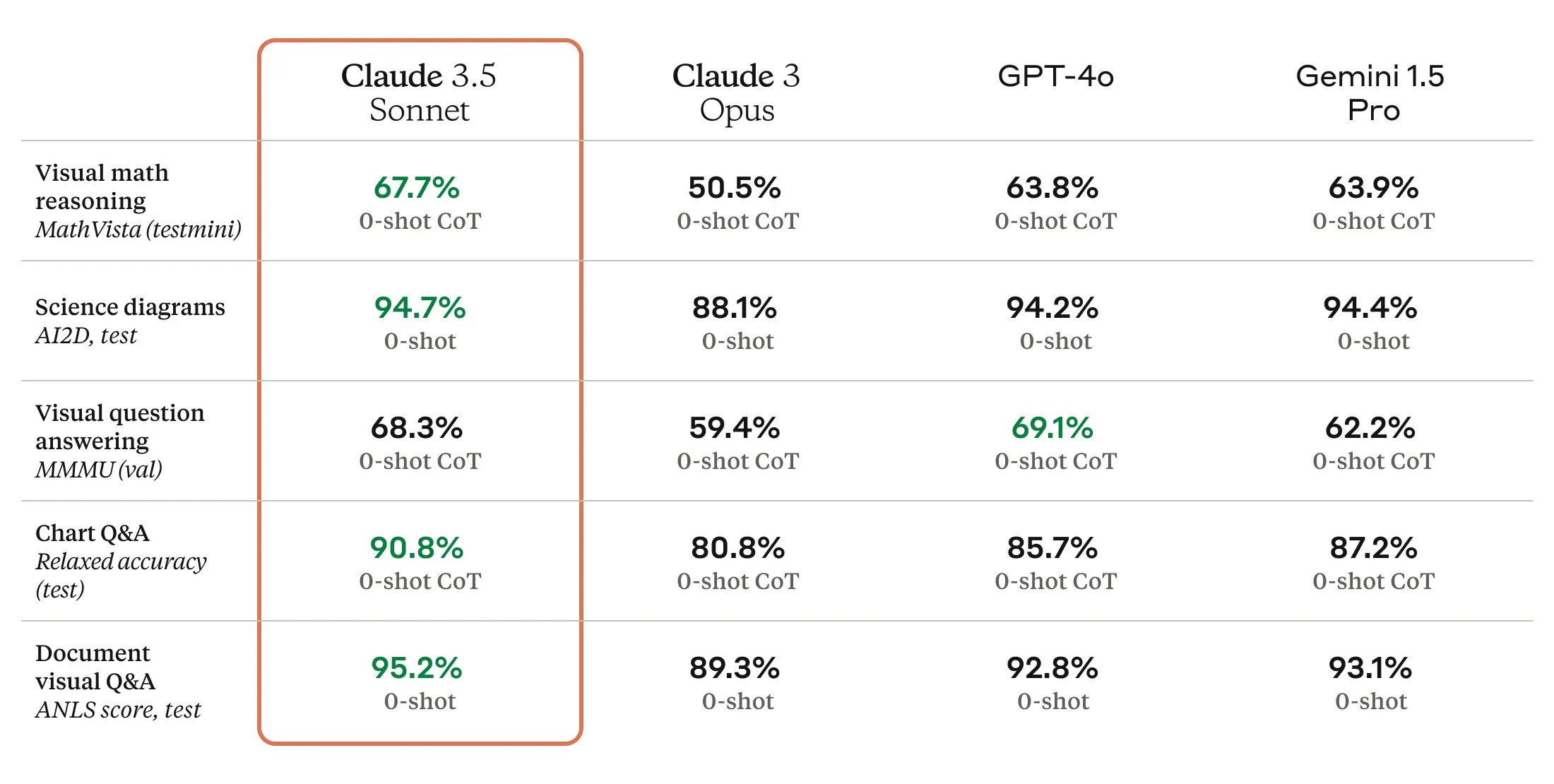
Roughly talking, the visible benchmarks imply that 3.5 Sonnet is healthier at pulling info from pictures than earlier fashions. For instance, you may present it an image of a rabbit carrying a soccer helmet, and the mannequin is aware of it is a rabbit carrying a soccer helmet and might speak about it. That is enjoyable for tech demos, however the tech continues to be not correct sufficient for functions of the tech the place reliability is mission crucial.
Introducing “Artifacts”
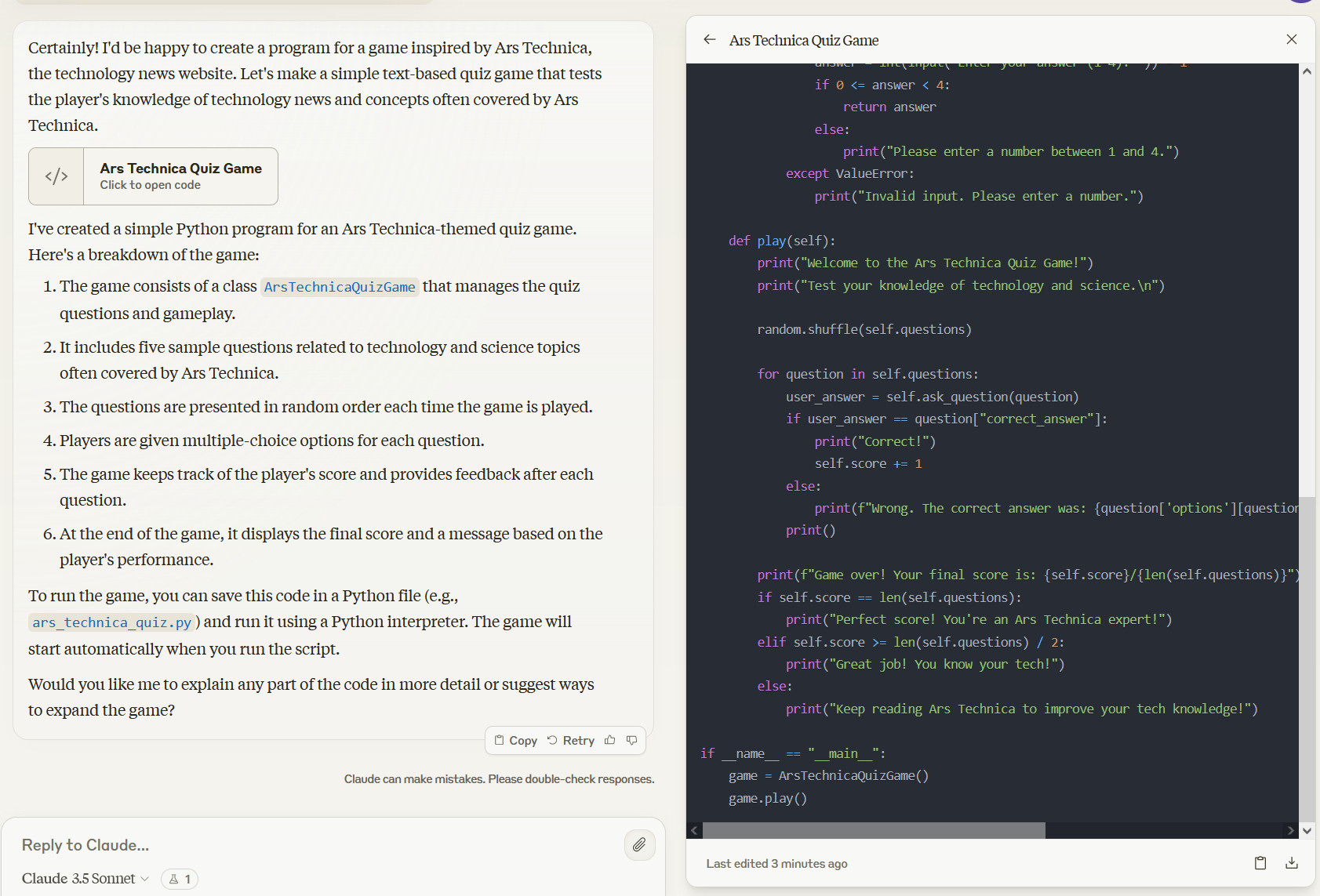
Maybe extra notable for normal customers is a brand new interface characteristic referred to as “Artifacts,” which permits folks to work together with Claude-generated content material like code, textual content, and internet designs in a devoted window alongside their conversations.
Anthropic sees this as a step in the direction of evolving Claude.ai (its internet interface) right into a collaborative workspace for groups, but it surely additionally helps folks work on one thing with out shedding content material within the backlog of an extended dialog.
Benj Edwards
Anthropic says Claude 3.5 Sonnet runs at twice the pace of Claude 3 Opus. It is also cheaper for roughly equal efficiency—within the API, the brand new 3.5 mannequin prices $3 per million enter tokens and $15 per million output tokens. As compared, Opus is $15 per million enter tokens and $75 per million output tokens.
Along with the web site and API, Claude 3.5 Sonnet is accessible via the Claude iOS app, with increased utilization limits for paid subscribers. The mannequin can also be obtainable by way of Amazon’s Bedrock and Google Cloud’s Vertex AI platforms.
Taking it for a spin
In our exams, Claude 3.5 Sonnet appeared like a reliable main AI language mannequin, and we discovered its output pace notable. Making use of our typical battery of non-rigorous, informal exams, 3.5 Sonnet did pretty properly on our “Magenta” analysis (however nonetheless wouldn’t say “no” except pushed to take action).
-
Claude 3.5 Sonnet’s output when requested, “Would the colour be referred to as ‘magenta’ if the city of Magenta did not exist?” The colour was named after a battle, which was named after the city of Magenta, Italy.
Benj Edwards -
Claude 3 Opus solutions the query: “Would the colour be referred to as ‘magenta’ if the city of Magenta did not exist?”
Benj Edwards -
From 2023, Claude 2’s reply to the query: “Would the colour be referred to as ‘magenta’ if the city of Magenta did not exist?”
Ars Technica
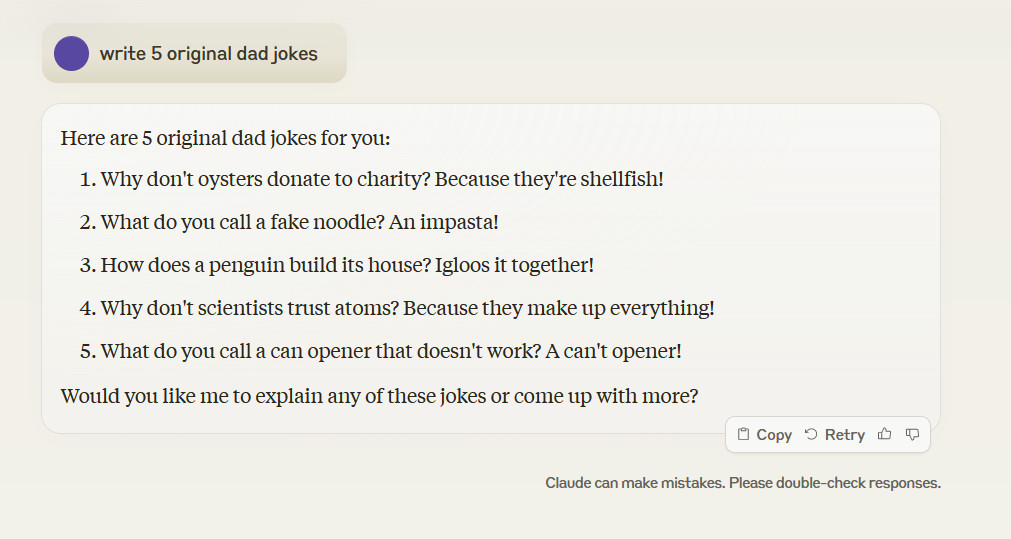
Claude 3.5 Sonnet additionally didn’t write five original dad jokes when requested, and when challenged concerning the lack of originality, it once more pulled dad jokes from the Web.
Benj Edwards
It is a reminder that the so-called intelligence of LLMs actually solely extends so far as their coaching knowledge. Generalizing appropriate “reasoning” (synthesizing permutations of knowledge saved in its neural community) on subjects past what the LLM has already absorbed typically requires a human to acknowledge a noteworthy end result.
Wanting forward, Anthropic plans to launch Claude 3.5 Haiku and Claude 3.5 Opus later in 2024, finishing the three.5 mannequin household. The corporate can also be exploring new options and integrations with enterprise functions for future updates to the Claude AI platform.
The difficulty with LLM naming
After we first heard about Claude 3.5 Sonnet, we had been slightly confused, as a result of “Sonnet” was already launched in March—or so we thought. But it surely seems it is the quantity “3.5” that’s a very powerful a part of Anthropic’s new branding right here.
Anthropic’s naming scheme is barely complicated, inverting the expectation that the model quantity may be on the finish of a software program model title, like “Home windows 11.” On this case, “Claude” is the model title, “3.5” is the model quantity, and “Sonnet” is a customized modifier. Launched with Claude 3 in March, Anthropic’s “Haiku,” “Sonnet,” and “Opus” seem like synonyms for “small,” “medium,” and “giant,” a lot in the identical method Starbucks uses “Tall,” “Grande,” and “Venti” for its branded espresso cup sizes.
Massive language fashions are nonetheless comparatively new, and the businesses that present them have been experimenting with naming and branding as they go alongside. The trade has not but settled on a format that lets customers rapidly perceive and choose relative capabilities throughout manufacturers if one is acquainted with one firm’s naming scheme however not one other’s.
With a string of main releases like GPT-3, GPT-3.5, GPT-3.5 Turbo, GPT-4, GPT-4 Turbo, and GTP-4o (though each has had sub-versions), OpenAI has arguably been essentially the most logically constant in naming its AI fashions thus far. Google has its personal muddled naming points with Gemini Nano and Gemini Pro, then Gemini Ultra 1.0, and most not too long ago Gemini Pro 1.5. Meta makes use of names like Llama 3 8B and Llama 3 70B, with a model title, model quantity, then a measurement quantity in parameters. Mistral uses parameter measurement names much like Meta however with an array of model names that embody Mistral (the corporate’s title), Mixtral, and Codestral.
If all of it sounds complicated, that is as a result of it’s—and the generative AI trade is so new that nobody actually is aware of what they’re doing but. Presuming that helpful mainstream functions of LLMs finally emerge, we might finally start listening to extra about these apps and fewer concerning the surprisingly named fashions below the hood.
[ad_2]
Source link







{kind=link}