

[ad_1]
Steady Diffusion XL Turbo / Benj Edwards
On Tuesday, Stability AI launched Stable Diffusion XL Turbo, an AI image-synthesis mannequin that may quickly generate imagery based mostly on a written immediate. So quickly, in reality, that the corporate is billing it as “real-time” picture era, since it could actually additionally rapidly remodel photographs from a supply, such as a webcam, rapidly.
SDXL Turbo’s major innovation lies in its potential to supply picture outputs in a single step, a major discount from the 20–50 steps required by its predecessor. Stability attributes this leap in effectivity to a way it calls Adversarial Diffusion Distillation (ADD). ADD makes use of rating distillation, the place the mannequin learns from present image-synthesis fashions, and adversarial loss, which reinforces the mannequin’s potential to distinguish between actual and generated photographs, bettering the realism of the output.
Stability detailed the mannequin’s internal workings in a research paper launched Tuesday that focuses on the ADD method. One of many claimed benefits of SDXL Turbo is its similarity to Generative Adversarial Networks (GANs), particularly in producing single-step picture outputs.
A promotional Steady Diffusion XL Turbo video from Stability AI.
SDXL Turbo photographs aren’t as detailed as SDXL photographs produced at greater step counts, so it isn’t thought-about a substitute of the earlier mannequin. However for the pace financial savings concerned, the outcomes are eye-popping.
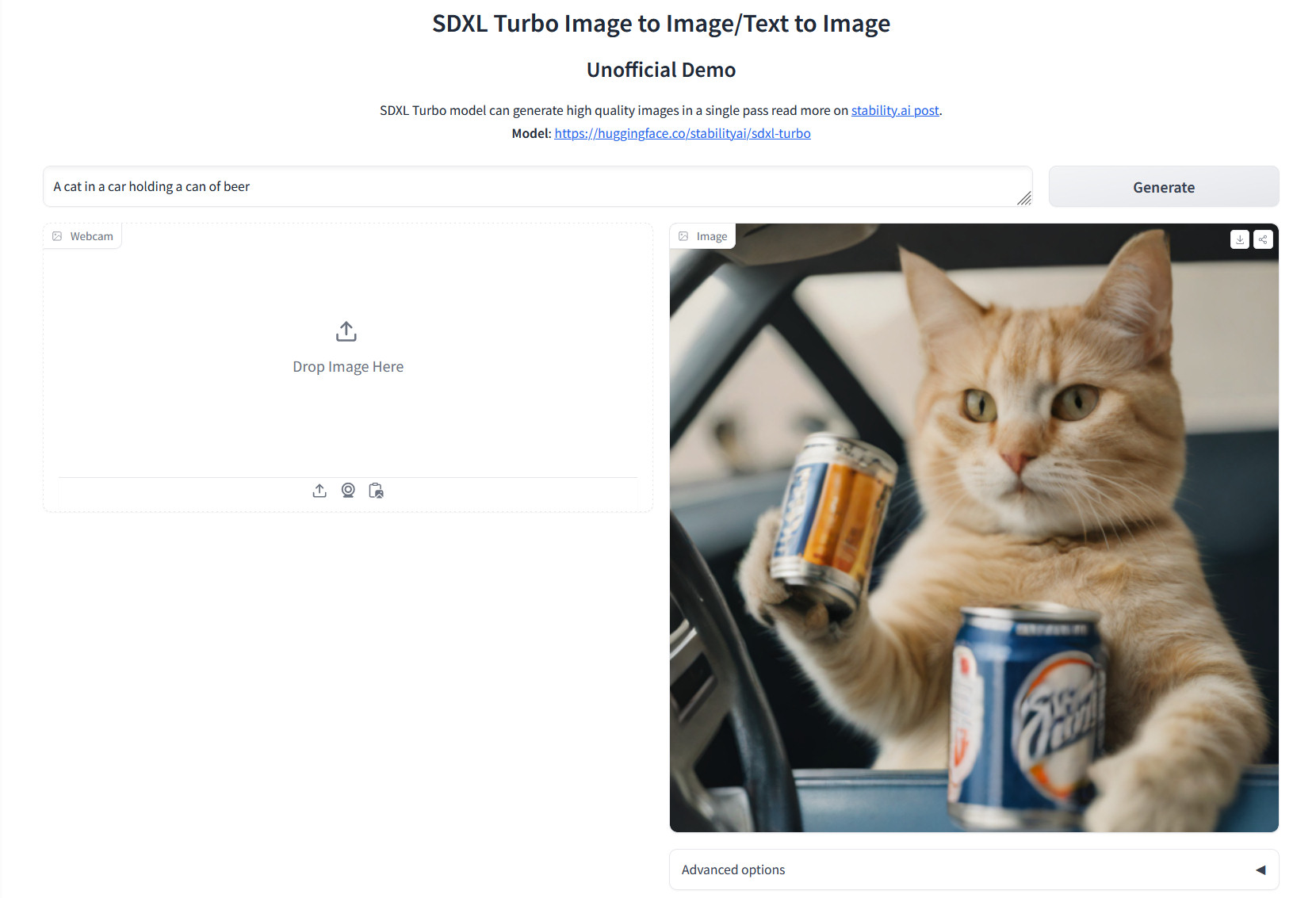
To strive it out, we ran SDXL Turbo regionally on an Nvidia RTX 3060 utilizing Automatic1111 (the weights drop in identical to SDXL weights), and it could actually generate a 3-step 1024×1024 picture in about 4 seconds, versus 26.4 seconds for a 20-step SDXL picture with related element. Smaller photographs generate a lot sooner (below one second for 512×768), and naturally, a beefier graphics card comparable to an RTX 3090 or 4090 will enable a lot faster era instances as nicely. Opposite to Stability’s advertising, we have discovered that SDXL Turbo photographs have the very best element at round 3–5 steps per picture.
SDXL Turbo’s era pace is the place the “real-time” declare is available in. Stability AI says that on an Nvidia A100 (a robust AI-tuned GPU), the mannequin can generate a 512×512 picture in 207 ms, together with encoding, a single de-noising step, and decoding. Speeds like that would result in real-time generative AI video filters or experimental online game graphics era, if coherency points could be solved. On this context, coherency means sustaining the identical topic between a number of frames or generations.
Ars Technica
At the moment, SDXL Turbo is accessible below a non-commercial analysis license, limiting its use to non-public, non-commercial functions. This transfer has already been met with some criticism within the Steady Diffusion group, however Stability AI has expressed openness to business functions and invitations events to get in contact for extra info.
In the meantime, Stability AI itself has confronted inside administration points, with an investor not too long ago urging CEO Emad Mostaque to resign. Stability administration has reportedly been exploring a possible firm sale to a bigger entity, however that hasn’t slowed down Stability’s cadence of releases. Simply final week, the agency introduced Stable Video Diffusion, which may flip nonetheless photographs into brief video clips.
Stability AI gives a beta demonstration of SDXL Turbo’s capabilities on its image-editing platform, Clipdrop. You too can experiment with an unofficial live demo on Hugging Face at no cost. Clearly all the same old caveats apply, together with the dearth of provenance for coaching information and the potential for misuse. Even with these unresolved points, technological progress in AI picture synthesis is actually not slowing down.
[ad_2]
Source link







{kind=link}
{kind=link}