

[ad_1]
On Monday, Anthropic released Claude 3, a household of three AI language fashions comparable to those who energy ChatGPT. Anthropic claims the fashions set new trade benchmarks throughout a variety of cognitive duties, even approaching “near-human” functionality in some instances. It is available now by Anthropic’s web site, with essentially the most highly effective mannequin being subscription-only. It is also obtainable by way of API for builders.
Claude 3’s three fashions signify growing complexity and parameter rely: Claude 3 Haiku, Claude 3 Sonnet, and Claude 3 Opus. Sonnet powers the Claude.ai chatbot now at no cost with an e-mail sign-in. However as talked about above, Opus is simply obtainable by Anthropic’s internet chat interface if you happen to pay $20 a month for “Claude Professional,” a subscription service provided by the Anthropic web site. All three function a 200,000-token context window. (The context window is the variety of tokens—fragments of a phrase—that an AI language mannequin can course of without delay.)
We coated the launch of Claude in March 2023 and Claude 2 in July that very same yr. Every time, Anthropic fell barely behind OpenAI’s greatest fashions in functionality whereas surpassing them when it comes to context window size. With Claude 3, Anthropic has maybe lastly caught up with OpenAI’s launched fashions when it comes to efficiency, though there isn’t any consensus amongst specialists but—and the presentation of AI benchmarks is notoriously vulnerable to cherry-picking.
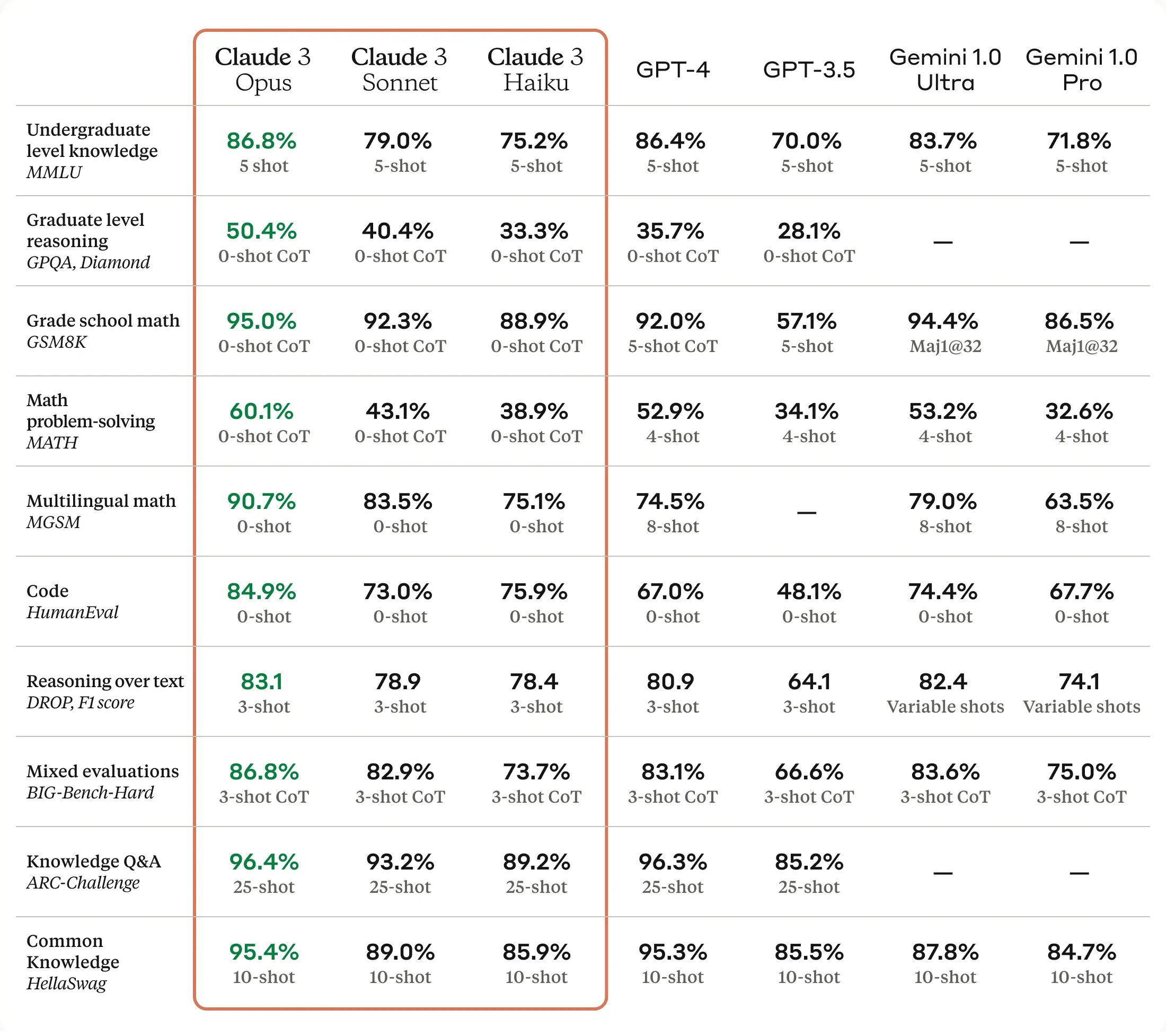
Claude 3 reportedly demonstrates superior efficiency throughout varied cognitive duties, together with reasoning, knowledgeable data, arithmetic, and language fluency. (Regardless of the shortage of consensus over whether or not giant language fashions “know” or “cause,” the AI analysis neighborhood generally makes use of these phrases.) The corporate claims that the Opus mannequin, essentially the most able to the three, displays “near-human ranges of comprehension and fluency on advanced duties.”
That is fairly a heady declare and deserves to be parsed extra rigorously. It is most likely true that Opus is “near-human” on some particular benchmarks, however that does not imply that Opus is a common intelligence like a human (take into account that pocket calculators are superhuman at math). So, it is a purposely eye-catching declare that may be watered down with {qualifications}.
In keeping with Anthropic, Claude 3 Opus beats GPT-4 on 10 AI benchmarks, together with MMLU (undergraduate stage data), GSM8K (grade college math), HumanEval (coding), and the colorfully named HellaSwag (widespread data). A number of of the wins are very slender, corresponding to 86.8 % for Opus vs. 86.4 % on a five-shot trial of MMLU, and a few gaps are huge, corresponding to 90.7 % on HumanEval over GPT-4’s 67.0 %. However what which may imply, precisely, to you as a buyer is tough to say.
“As all the time, LLM benchmarks needs to be handled with a bit little bit of suspicion,” says AI researcher Simon Willison, who spoke with Ars about Claude 3. “How nicely a mannequin performs on benchmarks does not let you know a lot about how the mannequin ‘feels’ to make use of. However that is nonetheless an enormous deal—no different mannequin has overwhelmed GPT-4 on a variety of broadly used benchmarks like this.”
[ad_2]
Source link







{kind=link}
{kind=link}