

[ad_1]
On Tuesday, Google introduced Lumiere, an AI video generator that it calls “a space-time diffusion mannequin for practical video era” within the accompanying preprint paper. However let’s not child ourselves: It does an awesome job at creating movies of cute animals in ridiculous situations, corresponding to utilizing curler skates, driving a automobile, or enjoying a piano. Certain, it will probably do extra, however it’s maybe probably the most superior text-to-animal AI video generator but demonstrated.
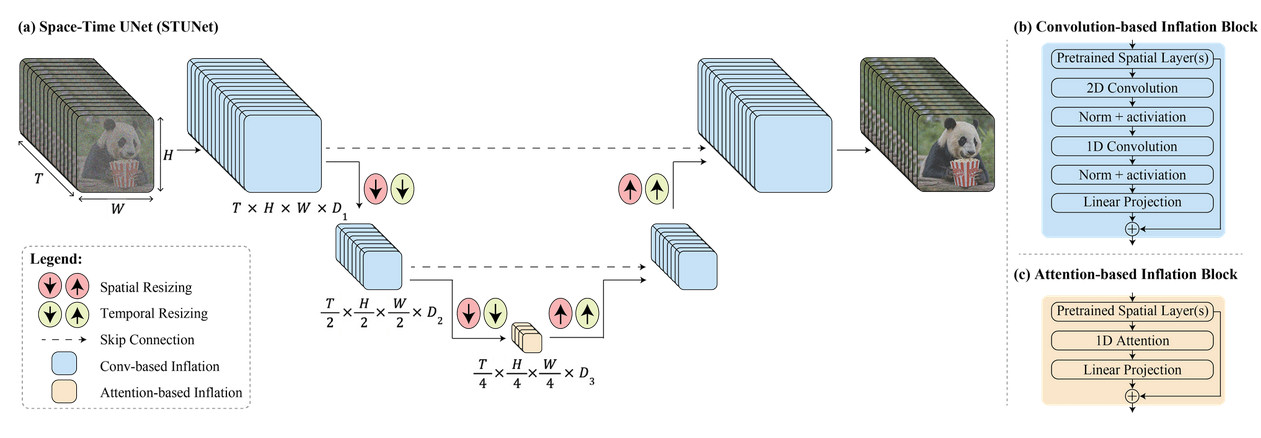
In accordance with Google, Lumiere makes use of distinctive structure to generate a video’s whole temporal length in a single go. Or, as the corporate put it, “We introduce a House-Time U-Web structure that generates the complete temporal length of the video directly, by way of a single move within the mannequin. That is in distinction to present video fashions which synthesize distant keyframes adopted by temporal super-resolution—an method that inherently makes international temporal consistency tough to attain.”
In layperson phrases, Google’s tech is designed to deal with each the area (the place issues are within the video) and time (how issues transfer and alter all through the video) features concurrently. So, as an alternative of constructing a video by placing collectively many small components or frames, it will probably create the complete video, from begin to end, in a single easy course of.
The official promotional video accompanying the paper “Lumiere: A House-Time Diffusion Mannequin for Video Era,” launched by Google.
Lumiere can even do loads of get together methods, that are laid out fairly nicely with examples on Google’s demo page. For instance, it will probably carry out text-to-video era (turning a written immediate right into a video), convert nonetheless photos into movies, generate movies in particular types utilizing a reference picture, apply constant video modifying utilizing text-based prompts, create cinemagraphs by animating particular areas of a picture, and supply video inpainting capabilities (for instance, it will probably change the kind of costume an individual is carrying).
Within the Lumiere analysis paper, the Google researchers state that the AI mannequin outputs five-second lengthy 1024×1024 pixel movies, which they describe as “low-resolution.” Regardless of these limitations, the researchers carried out a consumer research and declare that Lumiere’s outputs have been most well-liked over present AI video synthesis fashions.
As for coaching information, Google does not say the place it bought the movies they fed into Lumiere, writing, “We prepare our T2V [text to video] mannequin on a dataset containing 30M movies together with their textual content caption. [sic] The movies are 80 frames lengthy at 16 fps (5 seconds). The bottom mannequin is skilled at 128×128.”
AI-generated video remains to be in a primitive state, nevertheless it’s been progressing in high quality over the previous two years. In October 2022, we lined Google’s first publicly unveiled picture synthesis mannequin, Imagen Video. It might generate brief 1280×768 video clips from a written immediate at 24 frames per second, however the outcomes weren’t at all times coherent. Earlier than that, Meta debuted its AI video generator, Make-A-Video. In June of final 12 months, Runway’s Gen2 video synthesis mannequin enabled the creation of two-second video clips from textual content prompts, fueling the creation of surrealistic parody commercials. And in November, we lined Stable Video Diffusion, which might generate brief clips from nonetheless photos.
AI corporations typically show video turbines with cute animals as a result of producing coherent, non-deformed people is at the moment tough—particularly since we, as people (you might be human, proper?), are adept at noticing any flaws in human our bodies or how they transfer. Simply take a look at AI-generated Will Smith eating spaghetti.
Judging by Google’s examples (and never having used it ourselves), Lumiere seems to surpass these different AI video era fashions. However since Google tends to maintain its AI analysis fashions near its chest, we’re unsure when, if ever, the general public might have an opportunity to strive it for themselves.
As at all times, each time we see text-to-video synthesis fashions getting extra succesful, we will not assist however consider the future implications for our Web-connected society, which is centered round sharing media artifacts—and the final presumption that “practical” video usually represents actual objects in actual conditions captured by a digicam. Future video synthesis instruments extra succesful than Lumiere will make misleading deepfakes trivially straightforward to create.
To that finish, within the “Societal Influence” part of the Lumiere paper, the researchers write, “Our major aim on this work is to allow novice customers to generate visible content material in an artistic and versatile means. [sic] Nonetheless, there’s a threat of misuse for creating pretend or dangerous content material with our expertise, and we imagine that it’s essential to develop and apply instruments for detecting biases and malicious use circumstances to be able to guarantee a protected and honest use.”
[ad_2]
Source link







{kind=link}
{kind=link}