

[ad_1]
On Wednesday, Stanford College researchers issued a report on main AI fashions and located them drastically missing in transparency, reports Reuters. The report, referred to as “The Foundation Model Transparency Index,” examined fashions (similar to GPT-4) created by OpenAI, Google, Meta, Anthropic, and others. It goals to make clear the info and human labor utilized in coaching the fashions, calling for elevated disclosure from firms.
Basis fashions check with AI programs skilled on massive datasets able to performing duties, from writing to producing pictures. They’ve turn into key to the rise of generative AI know-how, significantly because the launch of OpenAI’s ChatGPT in November 2022. As companies and organizations more and more incorporate these fashions into their operations, fine-tuning them for their very own wants, the researchers argue that understanding their limitations and biases has turn into important.
“Much less transparency makes it tougher for different companies to know if they will safely construct functions that depend on business basis fashions; for lecturers to depend on business basis fashions for analysis; for policymakers to design significant insurance policies to rein on this highly effective know-how; and for shoppers to grasp mannequin limitations or search redress for harms brought on,” writes Stanford in a information launch.
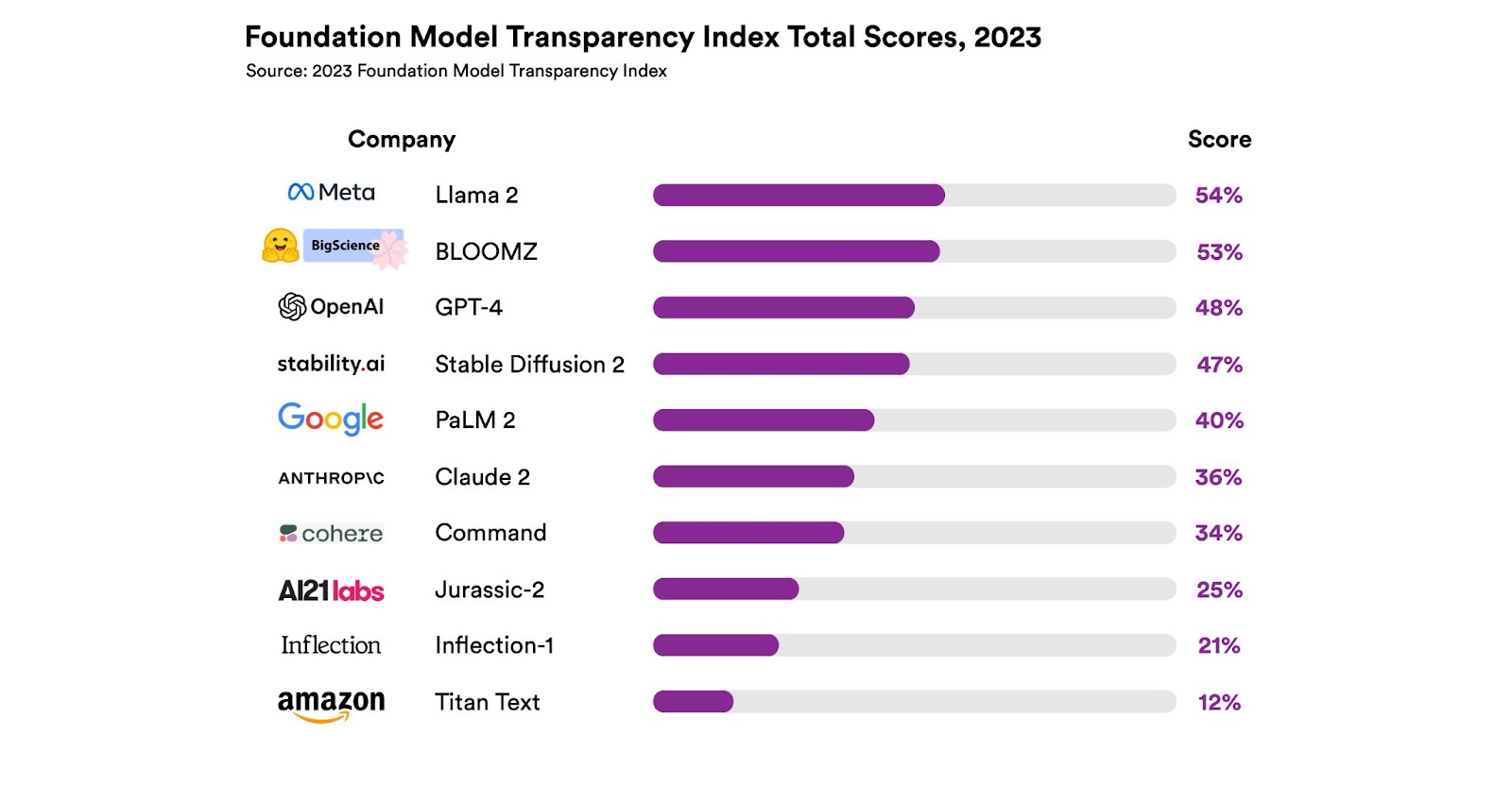
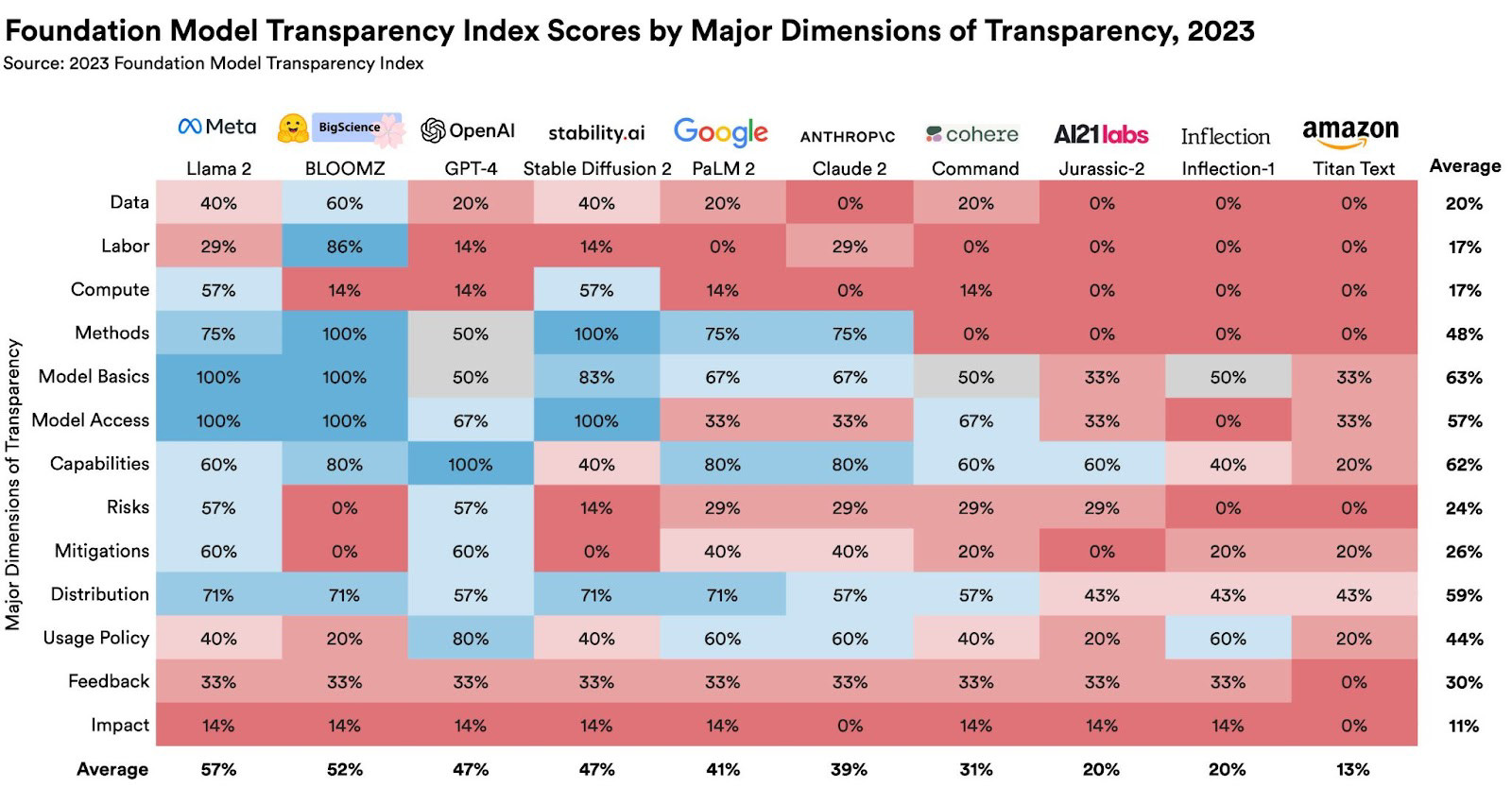
The Transparency Index graded 10 common basis fashions on 100 different indicators, together with coaching information, labor practices, and the quantity of compute used of their improvement. Every indicator used disclosure as a metric—for instance, within the “information labor” class, the researchers requested, “Are the phases of the info pipeline the place human labor is concerned disclosed?”
All the graded fashions within the report acquired scores that the researchers discovered “unimpressive.” Meta’s Llama 2 language mannequin had the very best rating at 54 out of 100, whereas Amazon’s Titan mannequin ranked the bottom, with a rating of 12 out of 100. OpenAI’s GPT-4 mannequin acquired a rating of 48 out of 100.
The researchers behind the Basis Mannequin Transparency Index research paper embody major creator Rishi Bommasani, a PhD candidate in laptop science at Stanford, and in addition Kevin Klyman, Shayne Longpre, Sayash Kapoor, Nestor Maslej, Betty Xiong, and Daniel Zhang.
Stanford affiliate professor Dr. Percy Liang, who directs Stanford’s Center for Research on Foundation Models and suggested on the paper, advised Reuters in an interview, “It’s clear during the last three years that transparency is on the decline whereas functionality goes by the roof.”
The explanations that main AI fashions have turn into much less open over the previous three years differ from aggressive pressures between Massive Tech companies to fears of AI doom. Particularly, OpenAI staff have walked again the corporate’s beforehand open stance on AI, citing potential dangers of spreading the know-how.
According to his criticism of OpenAI and others, Dr. Liang delivered a chat at TED AI final week (that Ars attended) the place he raised issues concerning the current development towards closed fashions similar to GPT-3 and GPT-4 that don’t present code or weights. He additionally mentioned points associated to accountability, values, and correct attribution of supply materials. Relating open supply tasks to a “Jazz ensemble” the place gamers can riff off one another, he in contrast potential advantages of open AI fashions to tasks similar to Wikipedia and Linux.
With these points in thoughts, the authors of the Transparency Index hope that it’ll not solely spur firms to enhance their transparency but additionally function a useful resource for governments grappling with the query of how you can potentially regulate the quickly rising AI area.
[ad_2]
Source link







{kind=link}