

[ad_1]
Ars Technica
On Thursday, Microsoft researchers introduced a brand new text-to-speech AI mannequin referred to as VALL-E that may intently simulate an individual’s voice when given a three-second audio pattern. As soon as it learns a selected voice, VALL-E can synthesize audio of that individual saying something—and do it in a manner that makes an attempt to protect the speaker’s emotional tone.
Its creators speculate that VALL-E might be used for high-quality text-to-speech purposes, speech modifying the place a recording of an individual might be edited and adjusted from a textual content transcript (making them say one thing they initially did not), and audio content material creation when mixed with different generative AI fashions like GPT-3.
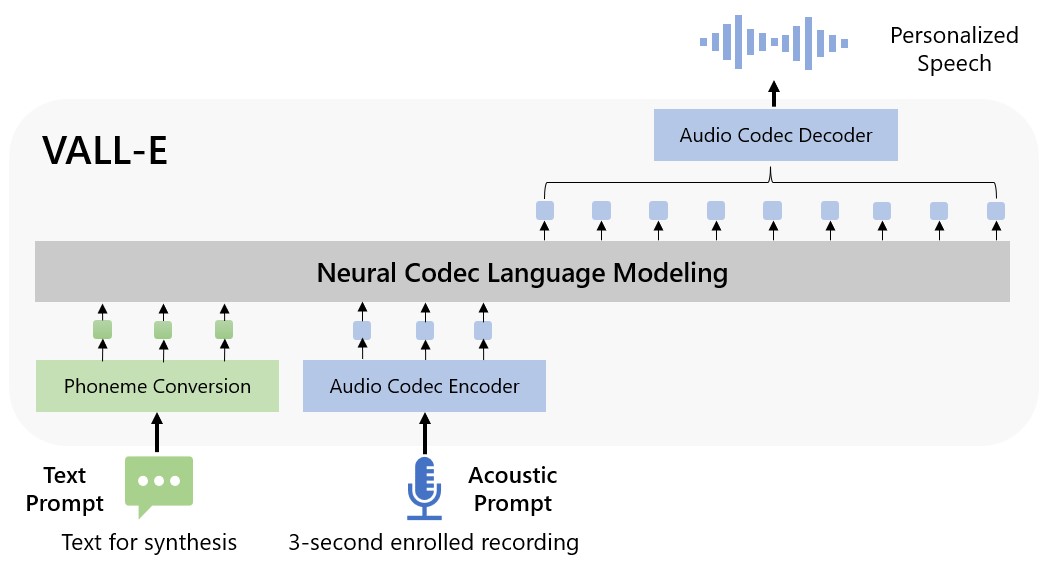
Microsoft calls VALL-E a “neural codec language mannequin,” and it builds off of a know-how referred to as EnCodec, which Meta announced in October 2022. In contrast to different text-to-speech strategies that sometimes synthesize speech by manipulating waveforms, VALL-E generates discrete audio codec codes from textual content and acoustic prompts. It mainly analyzes how an individual sounds, breaks that info into discrete elements (referred to as “tokens”) due to EnCodec, and makes use of coaching knowledge to match what it “is aware of” about how that voice would sound if it spoke different phrases outdoors of the three-second pattern. Or, as Microsoft places it within the VALL-E paper:
To synthesize customized speech (e.g., zero-shot TTS), VALL-E generates the corresponding acoustic tokens conditioned on the acoustic tokens of the 3-second enrolled recording and the phoneme immediate, which constrain the speaker and content material info respectively. Lastly, the generated acoustic tokens are used to synthesize the ultimate waveform with the corresponding neural codec decoder.
Microsoft educated VALL-E’s speech synthesis capabilities on an audio library, assembled by Meta, referred to as LibriLight. It accommodates 60,000 hours of English language speech from greater than 7,000 audio system, largely pulled from LibriVox public area audiobooks. For VALL-E to generate an excellent consequence, the voice within the three-second pattern should intently match a voice within the coaching knowledge.
On the VALL-E example website, Microsoft gives dozens of audio examples of the AI mannequin in motion. Among the many samples, the “Speaker Immediate” is the three-second audio supplied to VALL-E that it should imitate. The “Floor Fact” is a pre-existing recording of that very same speaker saying a specific phrase for comparability functions (kind of just like the “management” within the experiment). The “Baseline” is an instance of synthesis supplied by a standard text-to-speech synthesis methodology, and the “VALL-E” pattern is the output from the VALL-E mannequin.
Microsoft
Whereas utilizing VALL-E to generate these outcomes, the researchers solely fed the three-second “Speaker Immediate” pattern and a textual content string (what they needed the voice to say) into VALL-E. So examine the “Floor Fact” pattern to the “VALL-E” pattern. In some instances, the 2 samples are very shut. Some VALL-E outcomes appear computer-generated, however others may probably be mistaken for a human’s speech, which is the aim of the mannequin.
Along with preserving a speaker’s vocal timbre and emotional tone, VALL-E can even imitate the “acoustic atmosphere” of the pattern audio. For instance, if the pattern got here from a phone name, the audio output will simulate the acoustic and frequency properties of a phone name in its synthesized output (that is a flowery manner of claiming it is going to sound like a phone name, too). And Microsoft’s samples (within the “Synthesis of Range” part) display that VALL-E can generate variations in voice tone by altering the random seed used within the era course of.
Maybe owing to VALL-E’s capability to probably gas mischief and deception, Microsoft has not supplied VALL-E code for others to experiment with, so we couldn’t take a look at VALL-E’s capabilities. The researchers appear conscious of the potential social hurt that this know-how may carry. For the paper’s conclusion, they write:
“Since VALL-E may synthesize speech that maintains speaker id, it might carry potential dangers in misuse of the mannequin, reminiscent of spoofing voice identification or impersonating a selected speaker. To mitigate such dangers, it’s doable to construct a detection mannequin to discriminate whether or not an audio clip was synthesized by VALL-E. We may also put Microsoft AI Principles into observe when additional growing the fashions.”
[ad_2]
Source link







{kind=link}
{kind=link}