

[ad_1]
Ars Technica
On Thursday, a pair of tech hobbyists launched Riffusion, an AI mannequin that generates music from textual content prompts by creating a visible illustration of sound and changing it to audio for playback. It makes use of a fine-tuned model of the Stable Diffusion 1.5 picture synthesis mannequin, making use of visible latent diffusion to sound processing in a novel means.
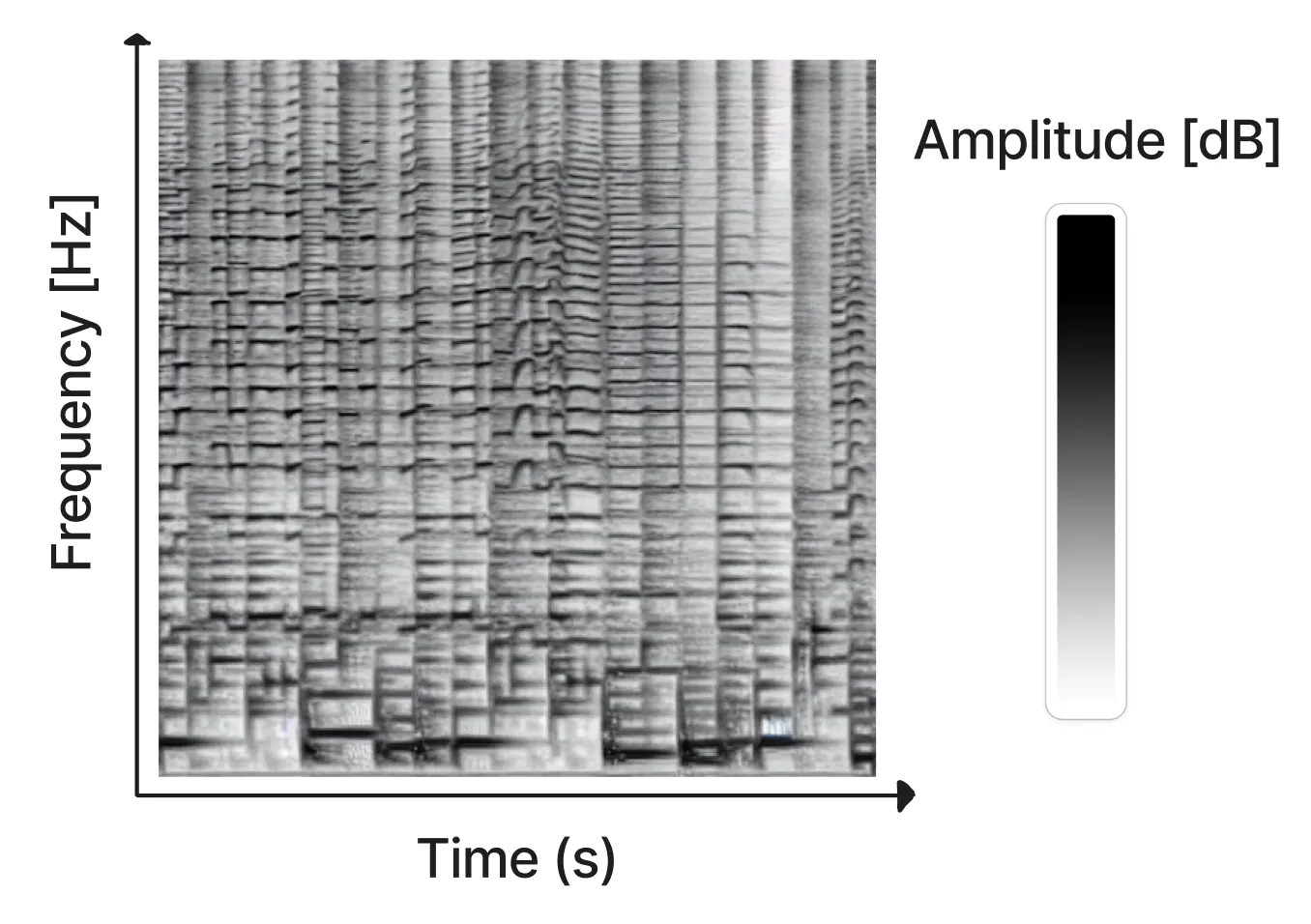
Created as a pastime mission by Seth Forsgren and Hayk Martiros, Riffusion works by producing sonograms, which retailer audio in a two-dimensional picture. In a sonogram, the X-axis represents time (the order through which the frequencies get performed, from left to proper), and the Y-axis represents the frequency of the sounds. In the meantime, the colour of every pixel within the picture represents the amplitude of the sound at that given second in time.
Since a sonogram is a kind of image, Steady Diffusion can course of it. Forsgren and Martiros educated a customized Steady Diffusion mannequin with instance sonograms linked to descriptions of the sounds or musical genres they represented. With that information, Riffusion can generate new music on the fly primarily based on textual content prompts that describe the kind of music or sound you need to hear, similar to “jazz,” “rock,” and even typing on a keyboard.
After producing the sonogram picture, Riffusion makes use of Torchaudio to vary the sonogram to sound, taking part in it again as audio.
“That is the v1.5 Steady Diffusion mannequin with no modifications, simply fine-tuned on pictures of spectrograms paired with textual content,” write Riffusion’s creators on its explanation page. “It could actually generate infinite variations of a immediate by various the seed. All the identical net UIs and strategies like img2img, inpainting, adverse prompts, and interpolation work out of the field.”
Guests to the Riffusion web site can experiment with the AI model because of an interactive net app that generates interpolated sonograms (easily stitched collectively for uninterrupted playback) in actual time whereas visualizing the spectrogram constantly on the left facet of the web page.

It could actually fuse types, too. For instance, typing in “easy tropical dance jazz” brings in parts of various genres for a novel end result, encouraging experimentation by mixing types.
In fact, Riffusion just isn’t the primary AI-powered music generator. Earlier this yr, Harmonai launched Dance Diffusion, an AI-powered generative music mannequin. OpenAI’s Jukebox, introduced in 2020, additionally generates new music with a neural community. And web sites like Soundraw create music continuous on the fly.
In comparison with these extra streamlined AI music efforts, Riffusion feels extra just like the pastime mission it’s. The music it generates ranges from attention-grabbing to unintelligible, nevertheless it stays a notable utility of latent diffusion expertise that manipulates audio in a visible house.
The Riffusion mannequin checkpoint and code are available on GitHub.
[ad_2]
Source link







{kind=link}
{kind=link}